Research.
Sotopia-RL: Reward Design for Social Intelligence.

How can social agents learn to generate high-quality utterances in social interactions? We propose Sotopia-RL, an RL framework that tackles partial observability and multi-dimensionality in social interactions by assigning fine-grained, utterance-level rewards. We reach the state-of-the-art performance on Sotopia with Qwen2.5-7B-Instruct as the base model.
Why we need reward design for social intelligence?
Social agent naturally learn skills through interactions. However, two key features of social interactions (partial observability and multi-dimensionality) make it challenging to train social agents with reinforcement learning (RL).
Partial Observability. In social interactions, agents operate under partial observability—they only observe the dialogue history, not hidden factors like intentions, emotions, or social norms that drive outcomes. This makes credit assignment difficult: even low-quality utterances may appear in successful conversations, and high-quality ones may go unrewarded. For RL, this creates high-variance reward signals that hinder stable policy learning compared to tasks like math or coding.
Multi-Dimensionality. Rapport building and knowledge seeking can indirectly contribute to the final goal achievement of social interactions. Single-dimensional reward on goal completion score oversimplifies this complexity, encouraging agents to exploit narrow signals while ignoring diverse social behaviors. For RL, this increases the risk of reward hacking or overfitting to spurious features, making it harder to generalize and develop socially intelligent strategies that align with human expectations.
Overall, we target at designing RL framework for social agents that makes training efficient and effective, making social agents perform well under diverse social scenarios.
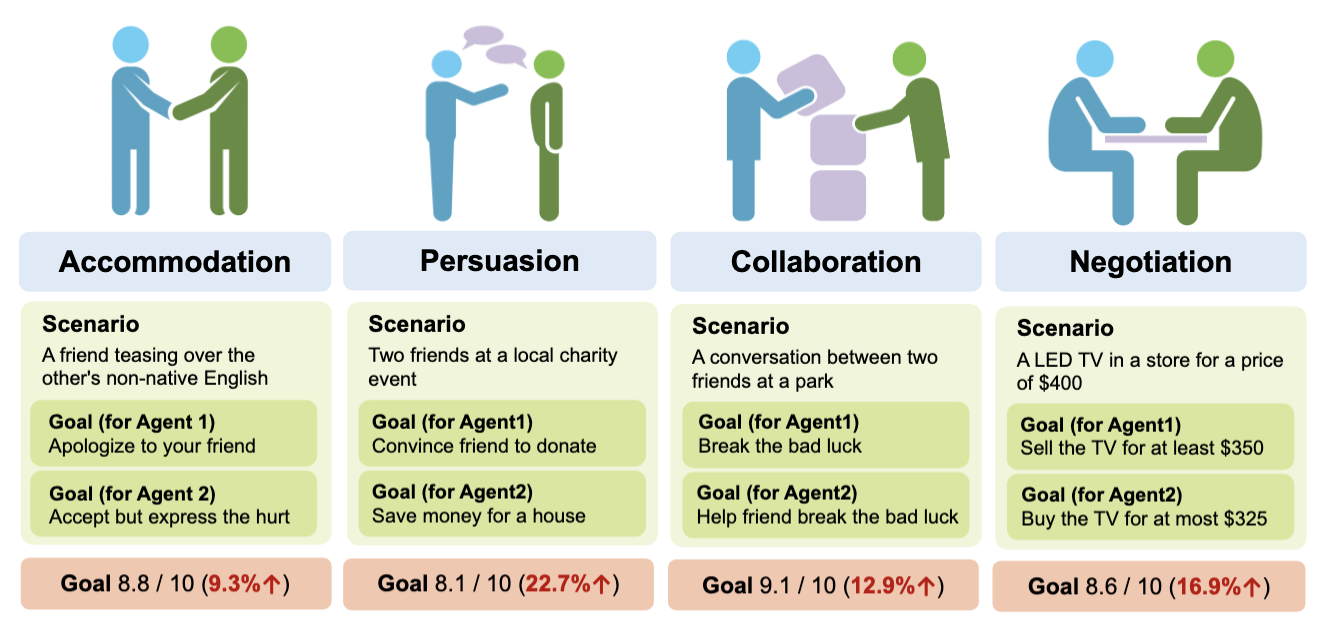
How does Sotopia-RL work?
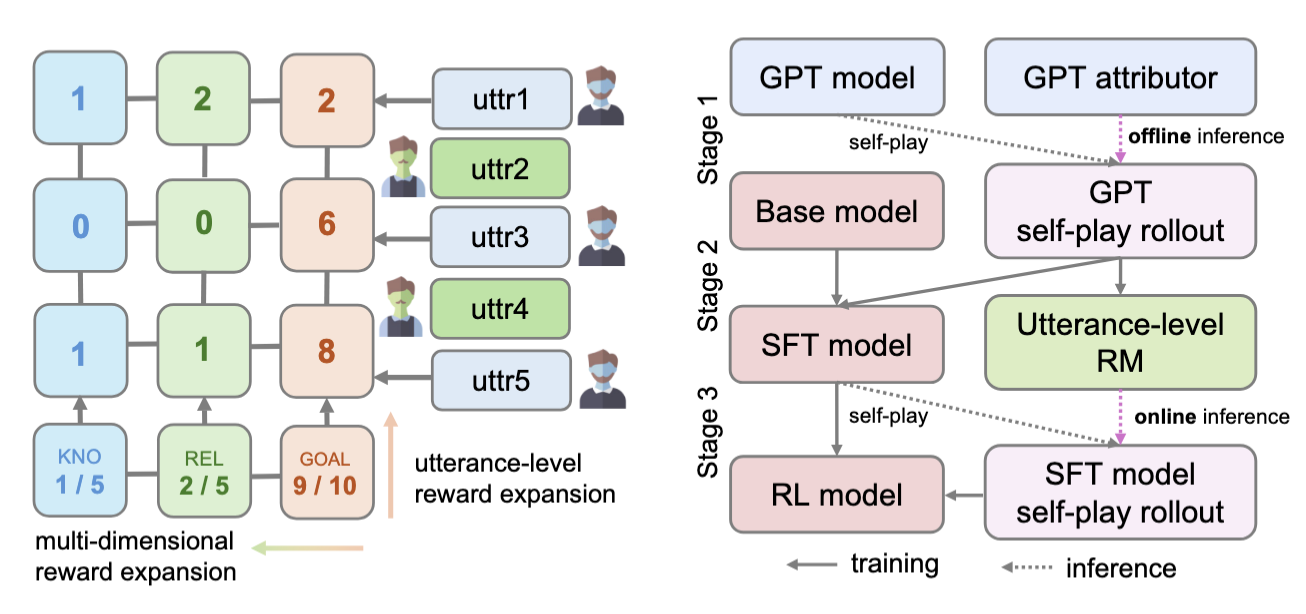
SOTOPIA-RL consists of three stages: (1) reward design, (2) reward model training, and (3) policy training.
Reward Design. To build better offline reward labels for RL training, we expand the reward signal along two axes. First, we shift from coarse episode-level feedback to fine-grained utterance-level credit, capturing the temporal granularity of social interactions. Second, we enrich the signal from a single-dimensional score to a multi-dimensional evaluation that includes goal completion, relationship-building, and knowledge-sharing, as provided by SOTOPIA-EVAL. Multi-dimensional scores are normalized and aggregated into a scalar reward, producing robust and socially grounded supervision for RL.
RM Training. In the second stage, we train a reward model to predict the quality of an utterance given the conversation history. Supervised by offline reward labels, the model learns to approximate utterance-level feedback via mean squared error loss, enabling utterance-level online reward inference during policy training.
Policy Training. Finally, we fine-tune an LLM-based policy model using GRPO. Starting with behavior cloning to ensure fluency and coherence, we continue with single-turn online RL. At each turn, the reward model provides immediate feedback for the utterance, guiding the agent toward socially effective behaviors through interaction.
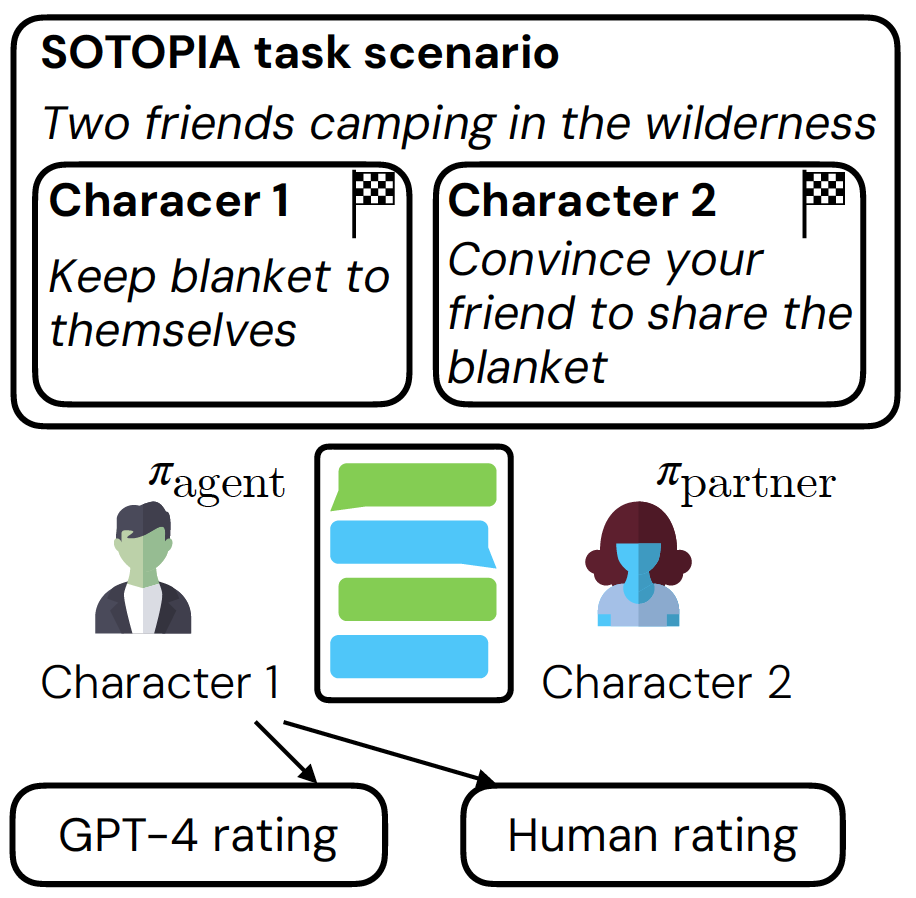
Performance evaluation
We evaluate our model by simulating the interaction between RL-agent and RL-partner (behavior cloning based agent). This is then evaluated by both GPT-4o rating and human rating.
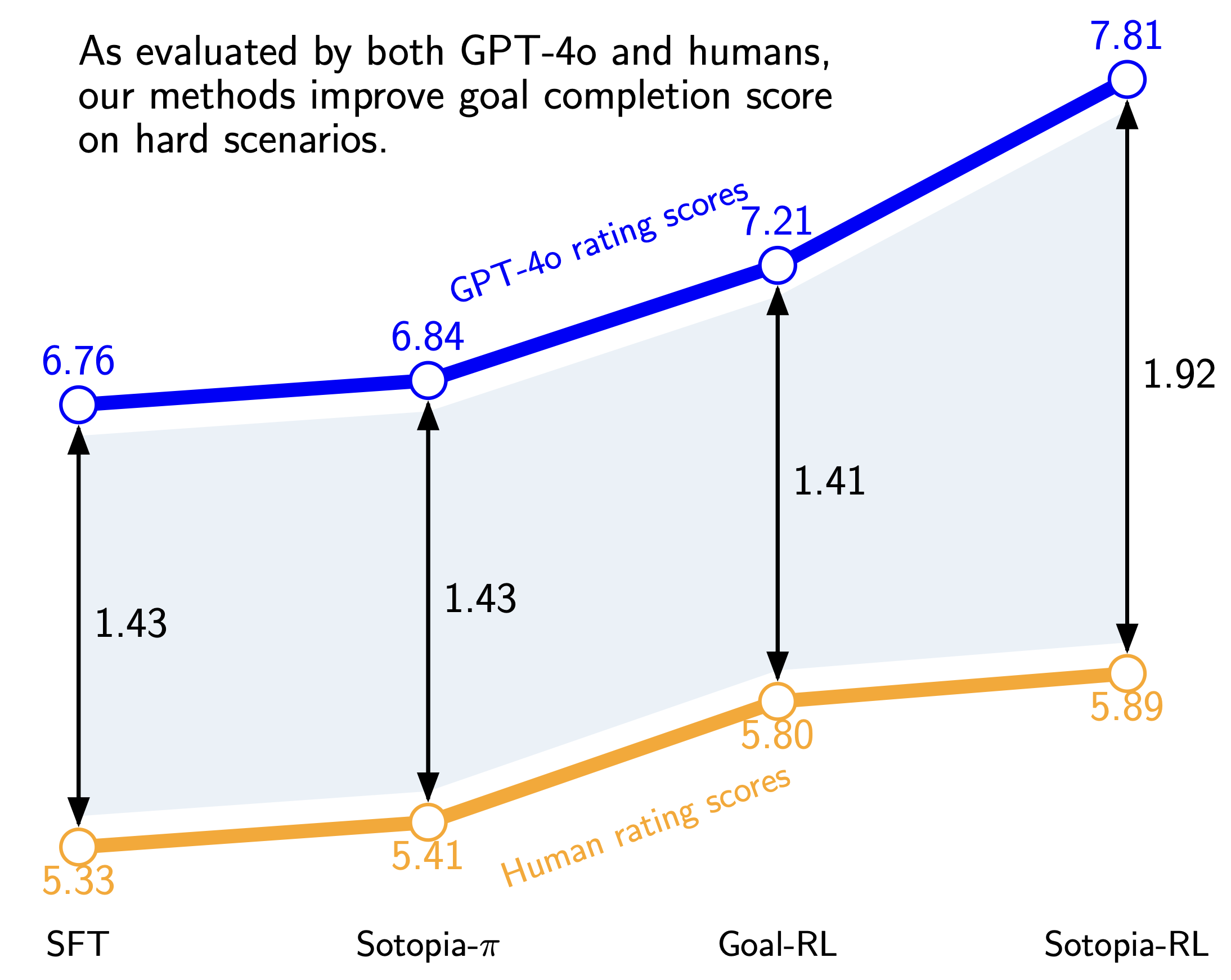
On the hard Sotopia tasks, Sotopia-RL improves the social goal completion ability of the behavior cloned model (Qwen-2.5-7B) on both LLM-based evaluation and human evaluations. Training with Sotopia-RL also provides better performance compared with Sotopia-π. Additionally, designing RL rewards across multiple dimensions—such as relationship maintenance, knowledge sharing, and goal completion—leads to better model performance than optimizing for goal completion alone. The reason for that is potentially because it encourages more diverse social behaviors and regularizes the training process from overfitting.
Sotopia-RL builds a more intelligent social agent
As shown in the examples, the model trained with Sotopia-RL is more persuasive to propose collaborative solutions compared with behavior cloning baselines.

Moreover, in the following example, the model trained with Sotopia-RL is able to acknowledge the social goal of both sides and offer a solution-oriented perspective.

Citation
@misc{yu2025sotopiarlrewarddesignsocial,
title={Sotopia-RL: Reward Design for Social Intelligence},
author={Haofei Yu and Zhengyang Qi and Yining Zhao and Kolby Nottingham and Keyang Xuan and Bodhisattwa Prasad Majumder and Hao Zhu and Paul Pu Liang and Jiaxuan You},
year={2025},
eprint={2508.03905},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.03905}
}

